Support Vector Machines

Photo by Francesco Ungaro on Unsplash
Support Vector Machines (commonly abbreviated as SVM) is a supervised learning algorithm that finds the optimal \(n\)-dimensional hyperplane to perform binary classification using the predictor space. A variant of this algorithm known as Support Vector Regression was introduced to predict a continuous output.
Linear Separability
Assume that we are working with a \(n\)-dimensional feature space. If there exists a hyperplane that can split this feature space such that the two classes are perfectly separated, then we say that the data is linearly separable. This is what a linearly separable dataset might look like with two features:
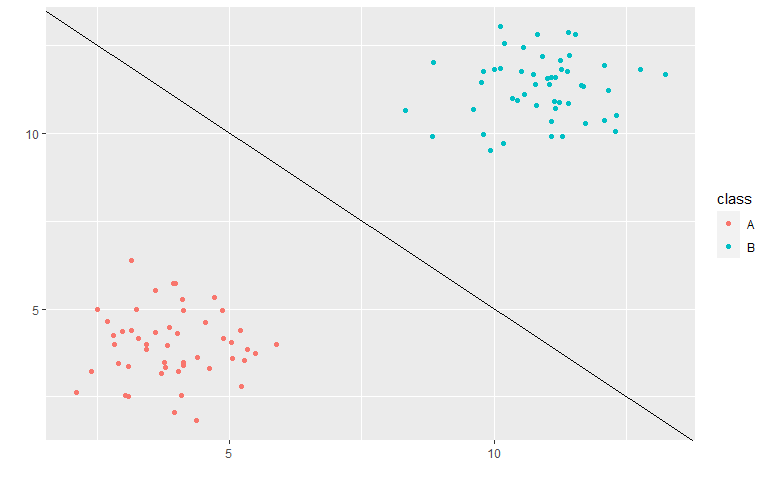
Linear SVM
The objective of a linear Support Vector Machine is to find the hyperplane that results in the maximum distance between the two classes. This is known as the maximum margin hyperplane.
The margin represents the region enclosed between the two closest points from either class. Finding the optimal hyperplane essentially becomes an optimization problem. The optimization objective and constraints depend on one important assumption.
Hard-margin SVMs
If we assume that the training data is linearly separable, then we can select two parallel hyperplanes to mark the boundaries of either class. The objective is to find the hyperplanes with the biggest margin. The maximum margin hyperplane will lie in the middle of these two hyperplanes.
Soft-margin SVMs
This is the case when the training data is not linearly separable (or when we think that subsequent observations will not be linearly separable). The objective function is two fold: we wish to minimize the error while trying to increase the distance between the margins.
The error is represented by the hinge loss function which evaluates to 0 if the observation is classified correctly (found on the right side of the hyperplane). When the observation is misclassified (found on the wrong side of the hyperplane), the hinge loss function evaluates to the distance from the hyperplane.
The \(C\) parameter determines the tradeoff between maximizing the margins and minimizing the hinge loss. For large values of \(C\), the algorithm will prioritize performance over margin width. A small value of \(C\) will prioritize finding the maximum margin hyperplane over performance.
In other words, as \(C\) approaches zero, the algorithm will behave similarly to a hard-margin SVM. The best way to choose \(C\) is by tuning the hyperparameter (train several SVMs with varying \(C\) values and select the value which yields the best performance).
Should I use hard margin or soft margin for my modeling problem?
Most software packages, including Sklearn, implement a soft-margin SVM. Since very few of us actually calculate the hyperplane formula by hand, the majority of Support Vector Machines actually assume that the data is not linearly separable.
But what if I know for a fact that the problem is linearly separable? Oftentimes, the soft-margin SVM will perform better than the hard-margin SVM even if that is true. Hard-margin SVMs are prone to overfitting (especially when there are outliers in the training data) due to the sole emphasis on maximizing the margin.
Non-linear SVMs
We can construct non-linear Support Vector Machines to tackle problems where the data is better divided by a non-linear boundary. We use the kernel trick to map the data into a higher dimensional space where we can approach the problem using a Linear SVM.
Consider this example where a linear classifier would perform poorly. The boundary of the dark orange circle is a more suitable separator between the two classes.
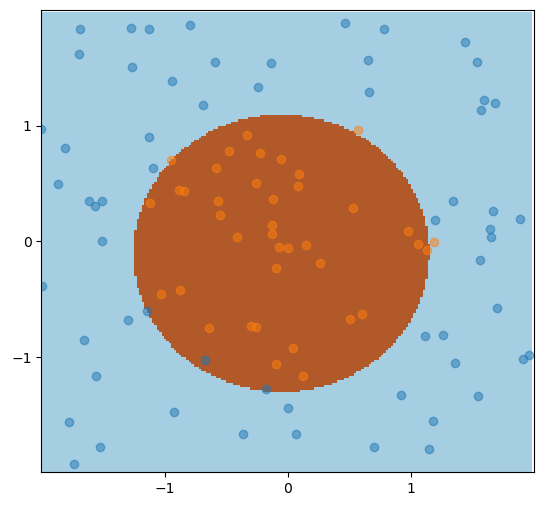
Using the radial basis function kernel from Sklearn, we can map this data to a linearly separable higher dimensional space.
Multi-class Classification
One of the drawbacks to Support Vector Machines is that it can only classify two classes at a time. The most common way of supporting multi-class classification is to train and compare multiple binary classifiers.
We can either use a one-versus-all approach where each class is pitted against the rest and the class with the highest score (furthest distance from the margin) is predicted. Alternatively, we can use a one-versus-one approach where each class is compared against all of the other classes and the class with the most votes is predicted.